Using Plack Middleware for Better Database Debugging
Overview
This is a short article that shows how one can use the new Plack based Catalyst to integrate middleware components designed to assist developers understand how your database is performing. We also will discuss how having Plack as a core Catalyst technology can assist us in broadening our software ecosystem and involve a larger developer base. An example of the approach taken to port a Catalyst specific role to Plack middleware is given.
The distributions discussed will include: Plack::Middleware::DBIC::QueryLog, Plack::Middleware::Debug::DBIC::QueryLog and a trait for the Catalyst DBIx::Class model (Catalyst::Model::DBIC::Schema) called Catalyst::TraitFor::Model::DBIC::Schema::QueryLog::AdoptPlack.
Additionally, having some familiarity with Plack and with its debugging middleware, Plack::Middleware::Debug would be valuable.
Catalyst and Plack
One of the things that has been great about being a Catalyst developer is in how the project has been both able to maintain long term backward compatibility as well as adopt Perl / CPAN's latest and greatest. For example, a few years ago we ported the Catalyst codebase to Moose. This gave us a solid base not only for the core Catalyst code, but for people building websites on top of it.
Recently we completed the project to port Catalyst to use Plack as a core technology. I believe this will have a powerful impact on our future coding goals, since it will allow us to concentrate our available programming talent on the things that make Catalyst the most powerful and flexible MVC system for Perl. Over time I foresee much of what lives in the Catalyst::Plugin namespace become simple wrappers on top of Plack::Middleware This is a total win - win situation since it means we have less code that is specific to Catalyst (meaning even more time for core developers to spend on the most unique aspect of Catalyst) and it also means that we can levage the concentrated efforts of developers across the CPAN ecosystem. Not everyone is a Catalyst developer, and even those of us that are don't always need the full power and complexity of Catalyst. Having more code in Plack Middleware means that on those projects where I want a more light weight approach (such as Web::Simple) I have access to the same tools as I do with Catalyst for solving common problems like authentication and sessioning.
Integrating Plack::Middleware::Debug::DBIC::QueryLog with Catalyst
If you have been using Catalyst and DBIx::Class for a while, you probably have used DBIx::Class::QueryLog, which is a great tool for giving you better insight into how your database is performing. For quite a while we've had Catalyst::TraitFor::Model::DBIC::Schema::QueryLog, which is a trait that enables querylogging per request to your Catalyst application. However this great feature is locked into Catalyst using this approach. Instead, let's see what can happen if we extract that functionality.
Plack::Middleware::DBIC::QueryLog
Plack::DBIC::QueryLog is a simple bit of Plack middleware that places an
instance of DBIx::Class::QueryLog into your Plack $env under the key
plack.middleware.dbic.querylog. It also exposes some helper methods designed
to be a consistent interface for finding and creating that key. Here's how it
might look in your application:
use Plack::Builder;
use MyDatabaseEnabledCatalystApplication;
my $app = MyDatabaseEnabledCatalystApplication->psgi_app;
builder {
enable 'DBIC::QueryLog';
$app;
};
Now when you startup the application using plackup your will have a fresh
instance of DBIx::Class::QueryLog available for logging.
This middleware accepts arguments which match the interface given in
DBIx::Class::QueryLog. Anything that you can pass to the new method
of that class you can set via querylog_args:
builder {
enable 'DBIC::QueryLog',
querylog_args => {passthrough => 1};
$app;
};
passthrough is one of the more useful options, since it makes sure that the
querylog allows any database events it intercepts pass through down to whatever
logging you might be doing at your Catalyst application level. In many
cases when you are developing you might use the DBIC_TRACE environment
variable to help you understand what DBIx::Class is doing (in addition to
the Querylogger). Setting the passthrough option will allow you to do both.
Catalyst::TraitFor::Model::DBIC::Schema::QueryLog::AdoptPlack
Next, lets look at how to get this new querylog exposed to Catalyst. If you are using DBIx::Class with Catalyst, you are probably using Catalyst::Model::DBIC::Schema. This model gives you the basic functionality to connect to a database and expose your DBIC classes to your Catalyst application. It also has a clean interface for extending its functionality, which is based on Moose and Moose::Role. Basically you can wrap traits (which are just Moose::Roles) at setup on top of your Catalyst DBIC model. Since this is a configuration option, this means that you can have different traits applied in different environments. For example, in production you might be using replication, and you'd apply the trait Catalyst::TraitFor::Model::DBIC::Schema::Replicated. On the flip side, in development you might want to use the querylogger to help developers understand bottlenecks in their SQL. Here's an example:
Assuming you have a class called MyDatabaseEnabledCatalystApplication::Model::Schema which looks something like this:
package MyDatabaseEnabledCatalystApplication::Model::Schema;
use parent 'Catalyst::Model::DBIC::Schema';
1;
Then, in your configuration file, you have something like this (assuming you are using the standard Config::General)
<Model::Schema>
schema_class MyDatabaseEnabledCatalystApplication::Schema
traits QueryLog::AdoptPlack
<connect_info>
dsn dbi:Pg:dbname=mypgdb
user postgres
password ""
</connect_info>
</Model::Schema>
Again, a trait is just a Moose::Role that gets applied at setup time, via configuration, which will make it easy to have your debugging trait in development but not in production. Please review the documentation for Catalyst::Plugin::ConfigLoader if you need a refresher on how to use a configuration file and have different configurations for different purposes.
So that is it! Now, when Catalyst runs a request, any DBIx::Class events will be logged via the DBIx::Class::QueryLog which you have enabled via the Plack middleware you added above.
Plack::Middleware::Debug::DBIC::QueryLog
You are now logging queries, but you have no reporting tools or way to see the results of that logging. Luckily, Plack::Middleware::Debug offers us a standard approach for adding debuggin panels to your web application. Building on top of this system is straightforward. Here's how to take that querylog and have it displayed as a nicely formated debugging panel:
use Plack::Builder;
use Plack::Middleware::Debug;
use MyDatabaseEnabledCatalystApplication;
my $app = MyDatabaseEnabledCatalystApplication->psgi_app;
my $panels = Plack::Middleware::Debug->default_panels;
builder {
enable 'DBIC::QueryLog';
enable 'Debug', panels =>['DBIC::QueryLog', @$panels];
$app;
};
This creates a Plack::Middleware::Debug console that addes your querylog report to the default list of panels. If you run your application you should get a debug console similar to this one:
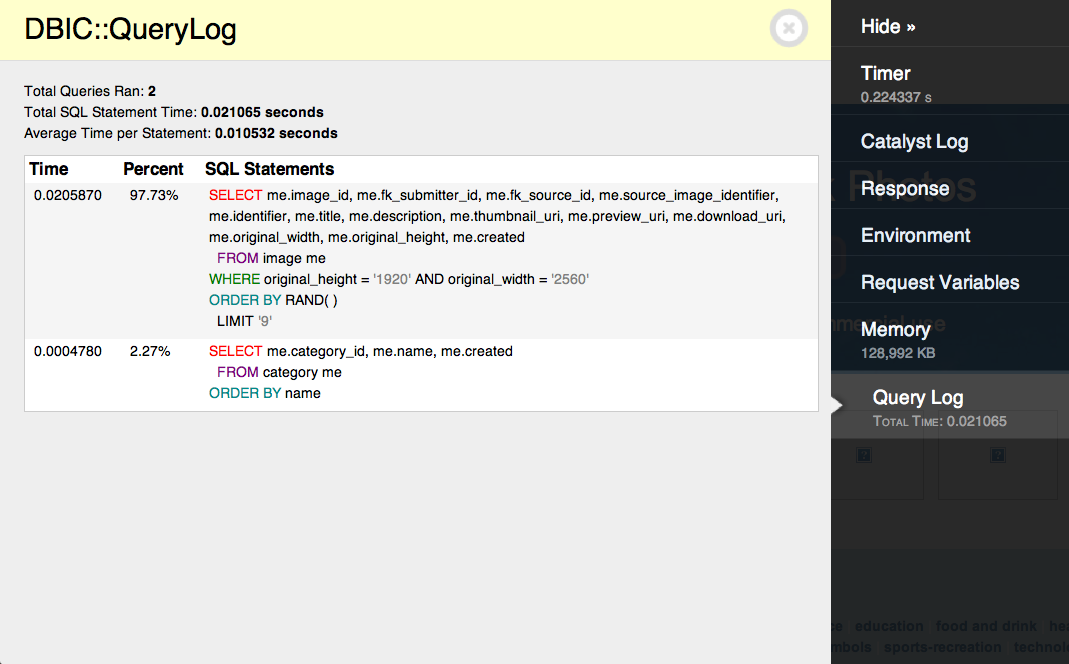
Control and Tweaks
Since the debug panel is a very common use case, it will automatically wrap the underlying Plack::Middleware::DBIC::QueryLog for you, which allows you to simplify your code a bit:
builder {
enable 'Debug', panels =>['DBIC::QueryLog', @$panels];
$app;
};
Generally I only manually add Plack::Middleware::DBIC::QueryLog when I have some sort of logging that lives outside the debugging panels. Additionally, you might want to only add the debug panels when you are in debugging mode, and you might wish to pass some arguments to the underlying DBIx::Class::QueryLog Here's a complete example:
use Plack::Builder;
use Plack::Middleware::Debug;
use MyDatabaseEnabledCatalystApplication;
my $app = MyDatabaseEnabledCatalystApplication->psgi_app;
my $panels = Plack::Middleware::Debug->default_panels;
builder {
enable_if {
$ENV{CATALYST_DEBUG}
} 'Debug', panels =>[['DBIC::QueryLog', passthrough=>1], @$panels];
$app;
};
For More Information
The source code for the three CPAN distributions discussed contain detailed examples and test cases, which are a great next step learning tool. I highly recommend reviewing them.
Summary
Having Plack as a core technology in Catalyst broadens the available software ecosystem you can access in order to do you job faster and better. However this is a two way street, so next time you are thinking of writing some Catalyst specific code, such as a plugin or a trait for some existing tool, you should consider how that functionality could be brought down to the Plack level. The code written to expose DBIx::Class::QueryLog via Plack middleware can serve as a decent example of how to do this.
Author
John Napiorkowski <jjnapiork@cpan.org> or jnap on IRC.
Thanks to Shutterstock (http://www.shutterstock.com/jobs.mhtml) for giving me a bit of time to review and craft this advent article.
- Previous
- Next